Related works
A Graph Theoretic Additive Approximation of Optimal Transport (LMR algorithm)
Related functions: cot.transport_lmr()
Abstract
Transportation cost is an attractive similarity measure between probability distributions due to its many useful theoretical properties. However, solving optimal transport exactly can be prohibitively expensive. Therefore, there has been significant effort towards the design of scalable approximation algorithms. Previous combinatorial results [Sharathkumar, Agarwal STOC ’12, Agarwal, Sharathkumar STOC ’14] have focused primarily on the design of near-linear time multiplicative approximation algorithms. There has also been an effort to design approximate solutions with additive errors [Cuturi NIPS ’13, Altschuler et al. NIPS ’17, Dvurechensky et al. ICML ’18, Quanrud, SOSA ’19] within a time bound that is linear in the size of the cost matrix and polynomial in \(C/\delta\); here \(C\) is the largest value in the cost matrix and \(\delta\) is the additive error. We present an adaptation of the classical graph algorithm of Gabow and Tarjan and provide a novel analysis of this algorithm that bounds its execution time by \(O(n^2 C/\delta + nC^2/\delta^2)\). Our algorithm is extremely simple and executes, for an arbitrarily small constant \(\varepsilon\), only \(\lfloor 2C/((1−\varepsilon)\delta)\rfloor+1\) iterations, where each iteration consists only of a Dijkstra-type search followed by a depth-first search. We also provide empirical results that suggest our algorithm is competitive with respect to a sequential implementation of the Sinkhorn algorithm in execution time. Moreover, our algorithm quickly computes a solution for very small values of δ whereas the Sinkhorn algorithm slows down due to numerical instability. [Full Paper]
Contributions
Novel Algorithm: The LMR algorithm adapts the classical Gabow-Tarjan cost-scaling approach, providing a new analysis that bounds its execution time by \(O(n^2 C/\delta + nC^2/\delta^2)\).

Table of execution time bounds.
Efficiency: The algorithm executes a limited number of iterations, each involving a Dijkstra-type search followed by a depth-first search. This makes it computationally efficient for very small values of the approximation parameter \(\delta\).
Empirical Results: The paper presents empirical results demonstrating that the proposed algorithm is competitive with the Sinkhorn algorithm, especially for small \(\delta\) values where the Sinkhorn algorithm suffers from numerical instability.
Experimental Results
The experimental results validate the theoretical bounds and show that the proposed algorithm outperforms existing methods in terms of both execution time and “number of iterations”.
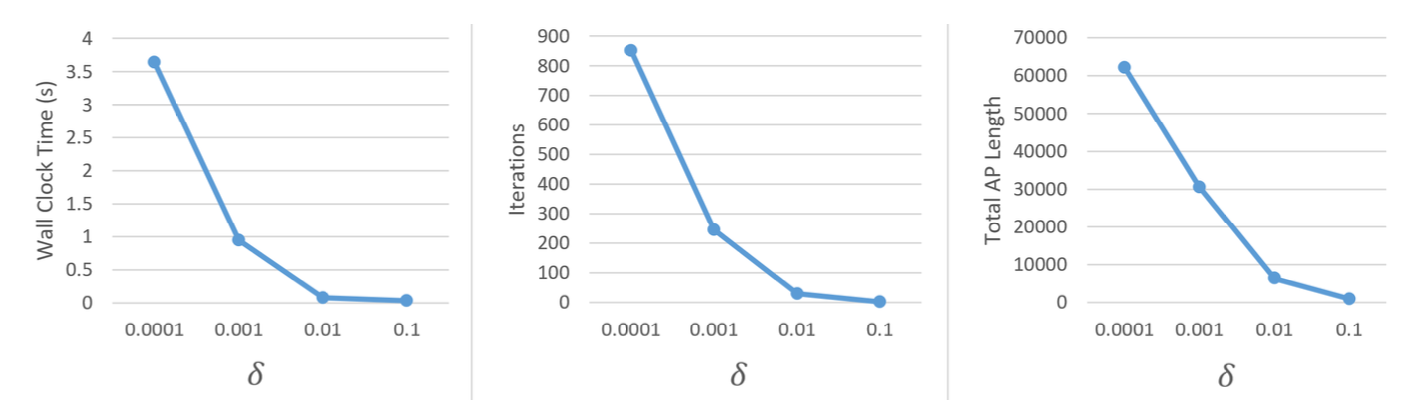
Efficiency statistics for our algorithm when executed on very small \(\delta\) values.
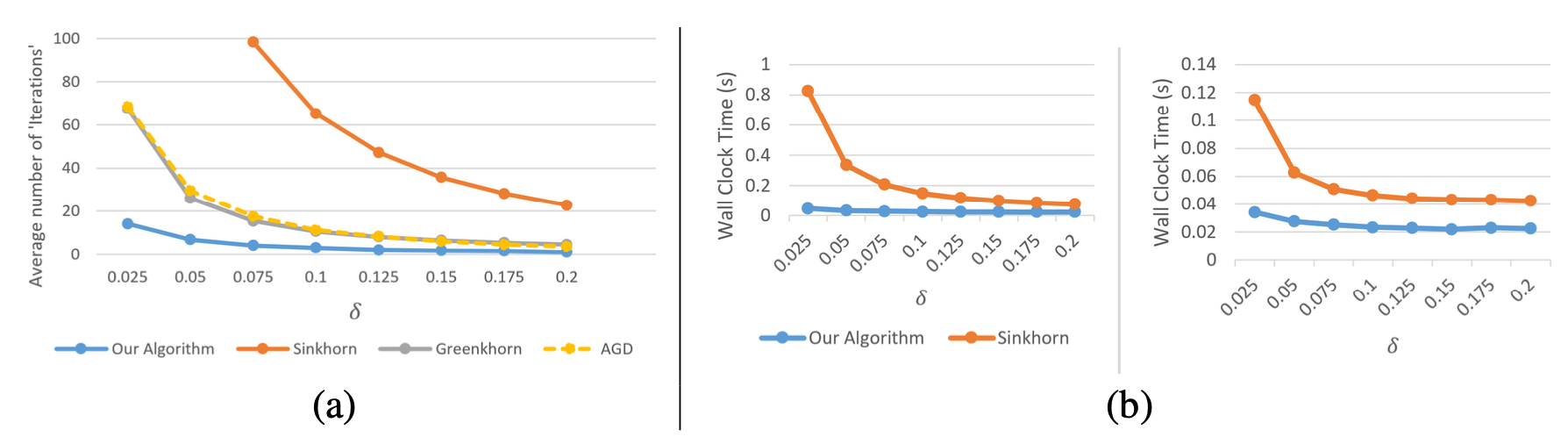
a: A comparison of the number of iterations executed by various algorithms for moderate values of \(\delta\); b: A comparison of our algorithm with the Sinkhorn algorithm using several \(\delta\) values. We compare running times when both algorithms receive \(\delta\) as input (left) and compare the running times when Sinkhorn receives \(5\delta\) and our algorithm receives \(\delta\) (right).
Citation
@article{lahn2019graph,
title={A graph theoretic additive approximation of optimal transport},
author={Lahn, Nathaniel and Mulchandani, Deepika and Raghvendra, Sharath},
journal={Advances in Neural Information Processing Systems},
volume={32},
year={2019}
}
A Combinatorial Algorithm for Approximating the Optimal Transport in the Parallel and MPC Settings
Related functions: cot.transport_torch(), cot.assignment_torch(), cot.assignment()
Abstract
Optimal Transport is a popular distance metric for measuring similarity between distributions. Exact and approximate combinatorial algorithms for computing the optimal transport distance are hard to parallelize. This has motivated the development of numerical solvers (e.g. Sinkhorn method) that can exploit GPU parallelism and produce approximate solutions.
We introduce the first parallel combinatorial algorithm to find an additive \(\varepsilon\)-approximation of the OT distance. The parallel complexity of our algorithm is \(O(\log(n)/ \varepsilon^2)\) where \(n\) is the total support size for the input distributions. In Massive Parallel Computation (MPC) frameworks such as Hadoop and MapReduce, our algorithm computes an \(\varepsilon\)-approximate transport plan in \(O(\log (\log (n/\varepsilon))/\varepsilon^2)\) rounds with \(O(n/\varepsilon)\) space per machine; all prior algorithms in the MPC framework take \(\Omega(\log n)\) rounds. We also provide a GPU-friendly matrix-based interpretation of our algorithm where each step of the algorithm is row or column manipulation of the matrix. Experiments suggest that our combinatorial algorithm is faster than the state-of-the-art approximate solvers in the GPU, especially for higher values of \(n\). [Full Paper]
Contributions
Parallel Algorithm: The proposed algorithm achieves a parallel complexity of \(O(log(n)/ε^2)\), where \(n\) is the total support size for the input distributions.
GPU-Friendly: The algorithm is also GPU-friendly, leveraging a matrix-based operations where each step involves row or column manipulation.
MPC Framework: In MPC frameworks such as Hadoop and MapReduce, the algorithm computes an \(ε\)-approximate transport plan in \(O(log(log(n/ε))/ε^2)\) rounds with \(O(n/ε)\) space per machine.
Experimental Results
Experimental results demonstrate the algorithm’s superior performance compared to Sinkhorn algorithm, especially for large datasets. Tests are conducted on synthetic and real-world data (e.g., MNIST images, word embedings) highlight the algorithm’s efficiency in terms of running time and number of iterations.
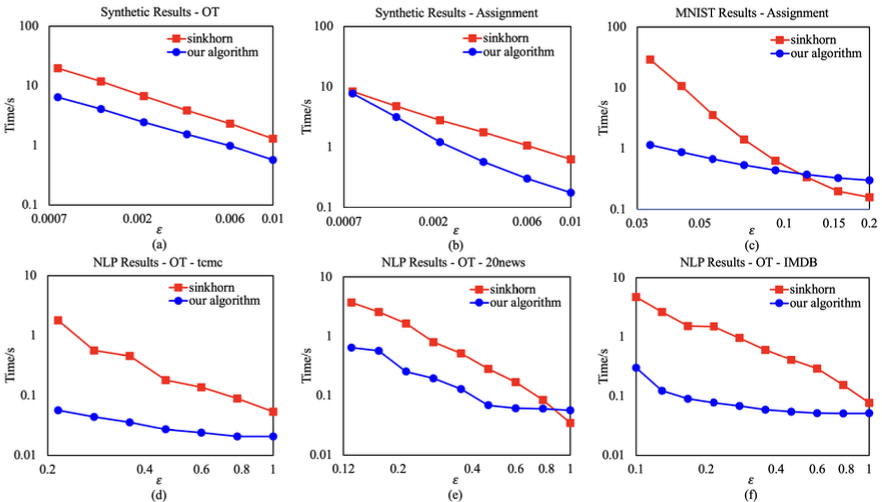
Plots of running times on GPU for the synthetic inputs (a)(b) and the real data inputs (c)(d)(e)(f).
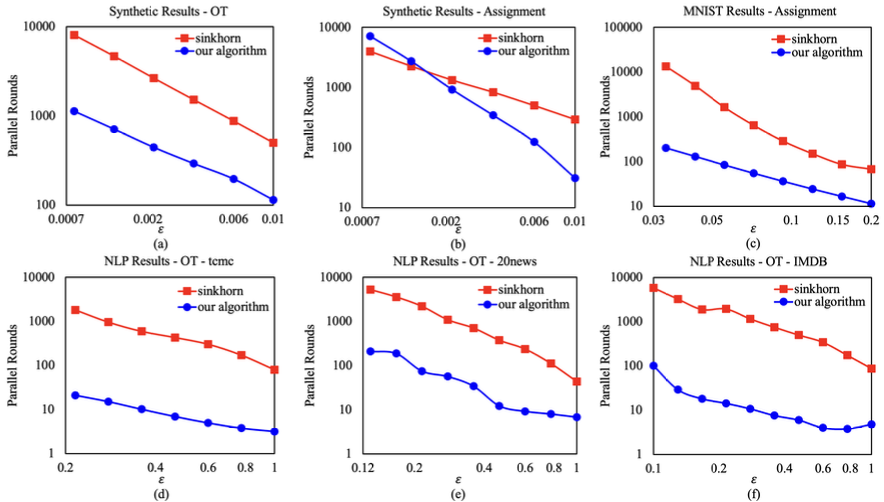
Plots of parallel rounds on GPU for the synthetic inputs (a)(b) and the real data inputs (c)(d)(e)(f).
Citation:
@article{lahn2023combinatorial,
title={A combinatorial algorithm for approximating the optimal transport in the parallel and mpc settings},
author={Lahn, Nathaniel and Raghvendra, Sharath and Zhang, Kaiyi},
journal={Advances in Neural Information Processing Systems},
volume={36},
pages={21675--21686},
year={2023}
}
Computing All Optimal Partial Transport
Related functions: cot.ot-profile()
Abstract
We consider the classical version of the optimal partial transport problem. Let \(\mu\) (with a mass of \(U\)) and \(\nu\) (with a mass of \(S\)) be two discrete mass distributions with \(S \le U\) and let \(n\) be the total number of points in the supports of \(\mu\) and \(\nu\). For a parameter \(\alpha \in [0,S]\), consider the minimum-cost transport plan \(\sigma_\alpha\) that transports a mass of \(\alpha\) from \(\nu\) to \(\mu\). An OT-profile captures the behavior of the cost of \(\sigma_\alpha\) as \(\alpha\) varies from 0 to \(S\). There is only limited work on OT-profile and its mathematical properties (see Figalli (2010)). In this paper, we present a novel framework to analyze the properties of the OT-profile and also present an algorithm to compute it. When \(\mu\) and \(\nu\) are discrete mass distributions, we show that the OT-profile is a piecewise-linear non-decreasing convex function. Let \(K\) be the combinatorial complexity of this function, i.e., the number of line segments required to represent the OT-profile. Our exact algorithm computes the OT-profile in \(\tilde{O}(n^2K)\) time. Given \(\delta > 0\), we also show that the algorithm by Lahn et al. (2019) can be used to \(\delta\)-approximate the OT-profile in \(O(n^2/\delta + n/\delta^2)\) time. This approximation is a piecewise-linear function of a combinatorial complexity of \(O(1/\delta)\).
An OT-profile is arguably more valuable than the OT-cost itself and can be used within applications. Under a reasonable assumption of outliers, we also show that the first derivative of the OT-profile sees a noticeable rise before any of the mass from outliers is transported. By using this property, we get an improved prediction accuracy for an outlier detection experiment. We also use this property to predict labels and estimate the class priors within PU-Learning experiments. Both these experiments are conducted on real datasets. [Full Paper]
Contributions:
Novel Framework: This work presents a framework to analyze the relationship between the cost of partial optimal transport and the transrpot mass, showing that it is a piecewise-linear, convex function, which is called OT-profile in this work.
Exact Algorithm: This work proposes a primal-dual based combinatorial algorithm to compute the exact OT profile in \(O(n^2 K)\) time, where \(K\) is the profile’s combinatorial complexity.
Approximation Algorithm: The paper presents an approximation algorithm that computes a \(δ\)-approximate OT profile in \(O(n^2/δ + n/δ^2)\) time.
Applications: The OT-profile is used to improve outlier detection and Positive Unlabelled (PU) learning, demonstrating its practical value.
Experimental Results:
Experiments validate the theoretical claims and showcase the algorithm’s performance on real-world datasets in missions of outlier detection and PU-Learning. The OT profile significantly improves outlier detection and PU learning accuracy witout the knowledge of the class priors.

Outlier detection accuracy comparison between OT-profile and existing methods.
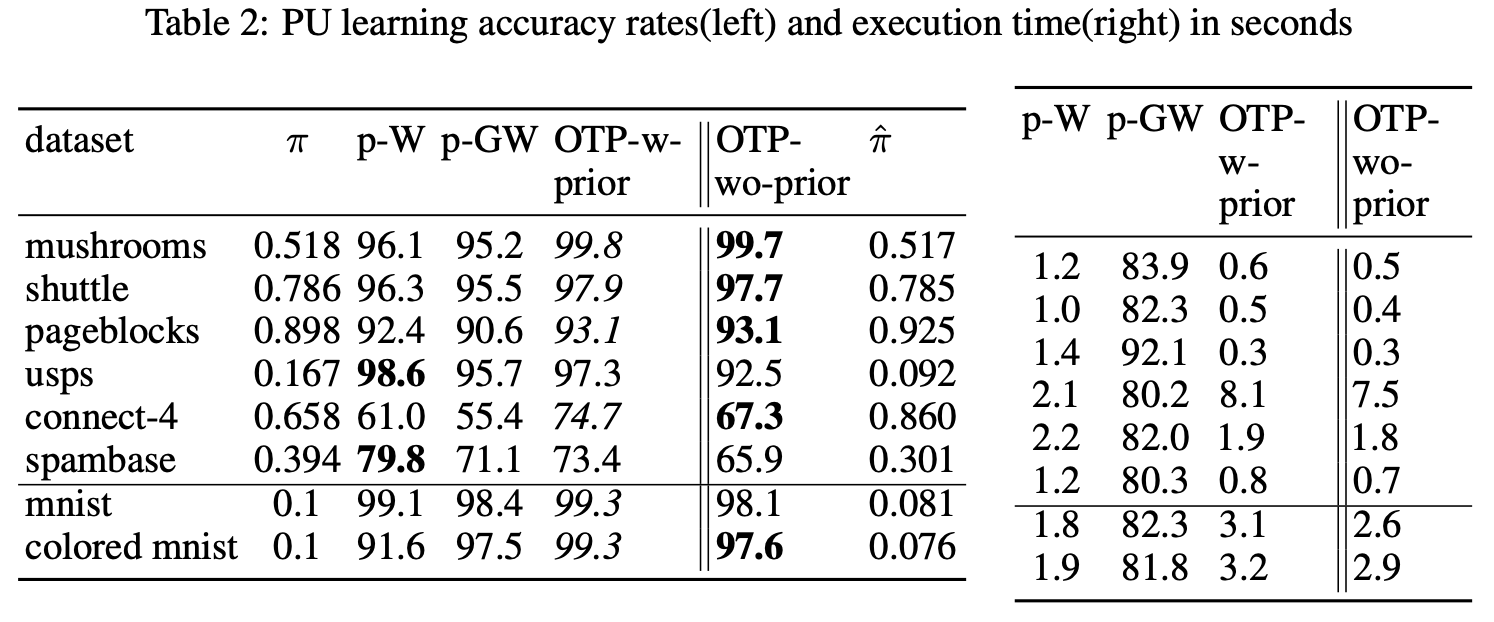
PU-learning accuracy rates for various datasets between OT-profile and existing methods.
Citation:
@inproceedings{phatak2023computing,
title={Computing all optimal partial transports},
author={Phatak, Abhijeet and Raghvendra, Sharath and Tripathy, Chittaranjan and Zhang, Kaiyi},
booktitle={International Conference on Learning Representations},
year={2023}
}
A New Robust Partial p-Wasserstein-Based Metric for Comparing Distributions
Related functions: cot.rpw_distance()
Abstract
The \(2\)-Wasserstein distance is sensitive to minor geometric differences between distributions, making it a very powerful dissimilarity metric. However, due to this sensitivity, a small outlier mass can also cause a significant increase in the \(2\)-Wasserstein distance between two similar distributions. Similarly, sampling discrepancy can cause the empirical \(2\)-Wasserstein distance on \(n\) samples in \(\mathbb{R}^2\) to converge to the true distance at a rate of \(n^{-1/4}\), which is significantly slower than the rate of \(n^{-1/2}\) for \(1\)-Wasserstein distance.
We introduce a new family of distances parameterized by \(k \ge 0\), called \(k\)-RPW, that is based on computing the partial \(2\)-Wasserstein distance. We show that (1) \(k\)-RPW satisfies the metric properties, (2) \(k\)-RPW is robust to small outlier mass while retaining the sensitivity of \(2\)-Wasserstein distance to minor geometric differences, and (3) when \(k\) is a constant, \(k\)-RPW distance between empirical distributions on \(n\) samples in \(\mathbb{R}^2\) converges to the true distance at a rate of \(n^{-1/3}\), which is faster than the convergence rate of \(n^{-1/4}\) for the \(2\)-Wasserstein distance.
Using the partial \(p\)-Wasserstein distance, we extend our distance to any \(p \in [1,\infty]\). By setting parameters \(k\) or \(p\) appropriately, we can reduce our distance to the total variation, \(p\)-Wasserstein, and the Lévy-Prokhorov distances. Experiments show that our distance function achieves higher accuracy in comparison to the \(1\)-Wasserstein, \(2\)-Wasserstein, and TV distances for image retrieval tasks on noisy real-world datasets. [Full Paper]

Interpretations of different distance functions.
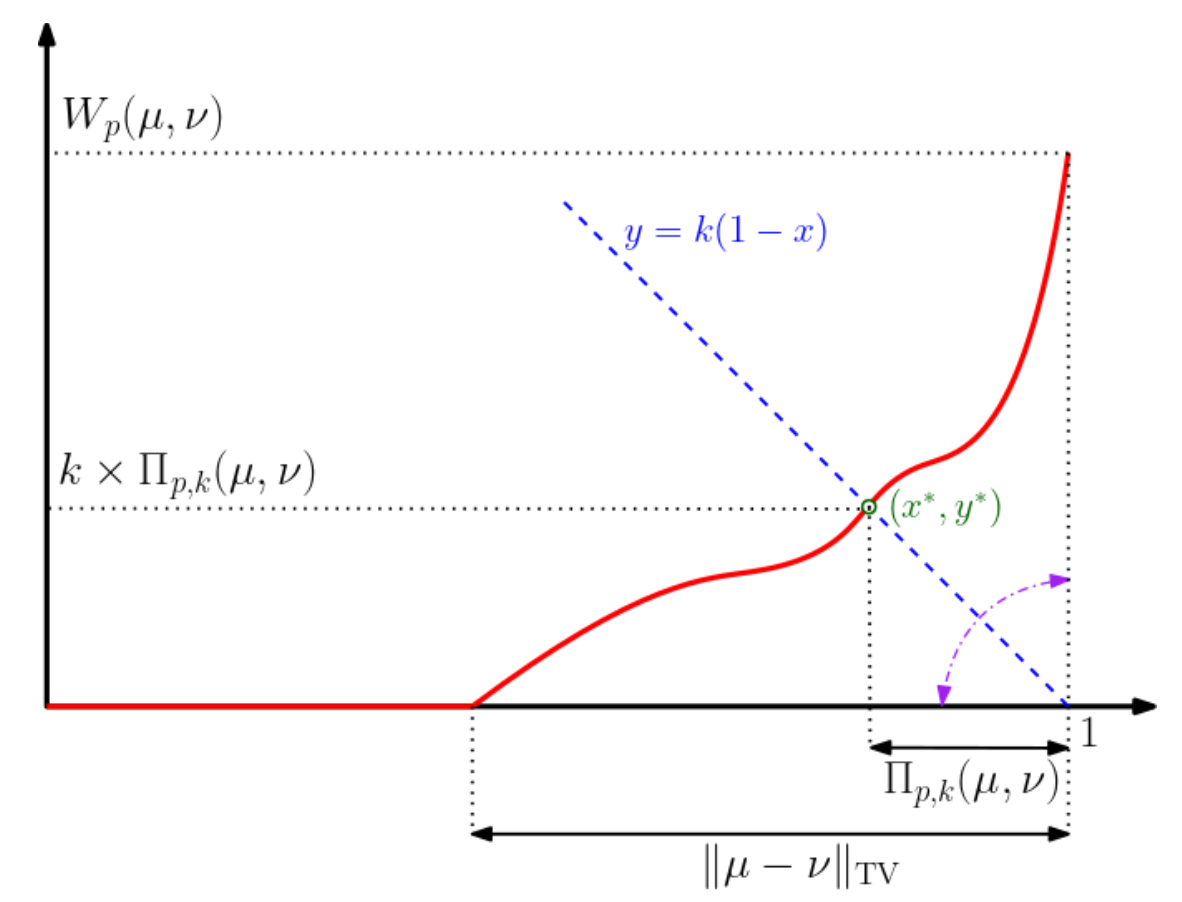
Interpretation of distances based on the OT-profile.
Contributions:
Metric Properties: The \(k\)-RPW distance satisfies the properties of a metric, including the triangle inequality.
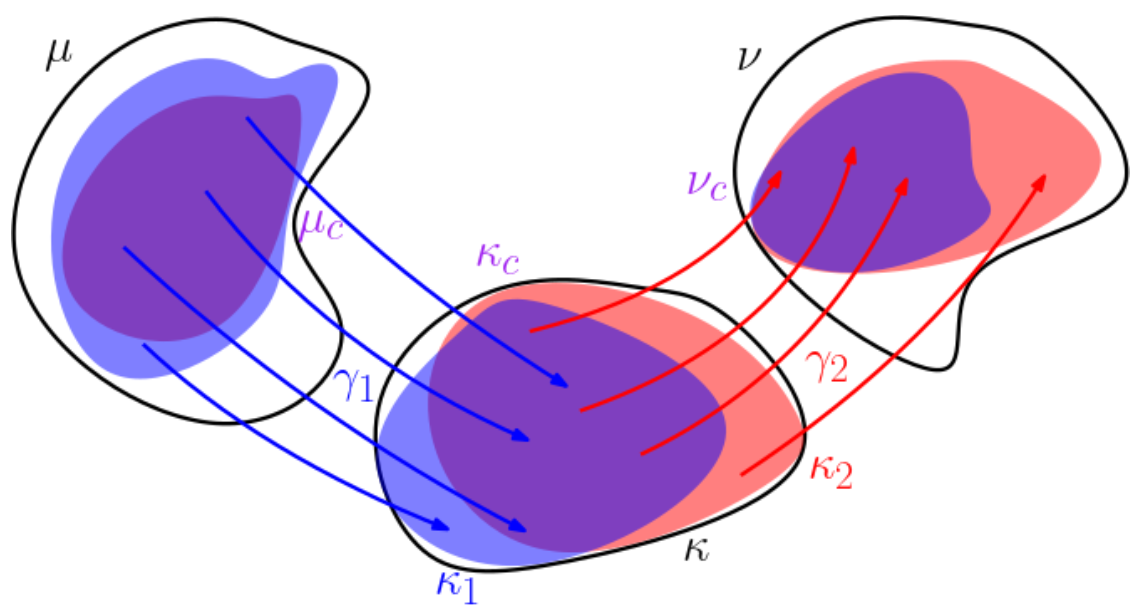
The triangle inequality of the RPW distance function.
Robustness: The \(k\)-RPW distance is robust to small outlier masses and sampling discrepancies, ensuring that minor noise does not disproportionately affect the distance.
Faster Convergence: The \(k\)-RPW distance between empirical distributions converges to the true distance at a faster rate compared to the \(2\)-Wasserstein distance.
Generalization: The partial \(p\)-Wasserstein distance is extended to any \(p \in [1, \infty]\) and \(k \in [0, \infty]\), allowing the metric to interpolate between total variation, \(p\)-Wasserstein, and Lévy-Prokhorov distances.
Experimental Results:
The experimental results demonstrate the effectiveness of the \(k\)-RPW distance in image retrieval task. The \(k\)-RPW distance outperforms the distances including \(1\)-Wasserstein, \(2\)-Wasserstein, and total variation (TV) distances in terms of accuracy in present of different types of perturbations. Additionaly, this work showcased the convergence rate of the \((2,k)\)-RPW distance is faster than the \(2\)-Wasserstein distance for empirical distributions.
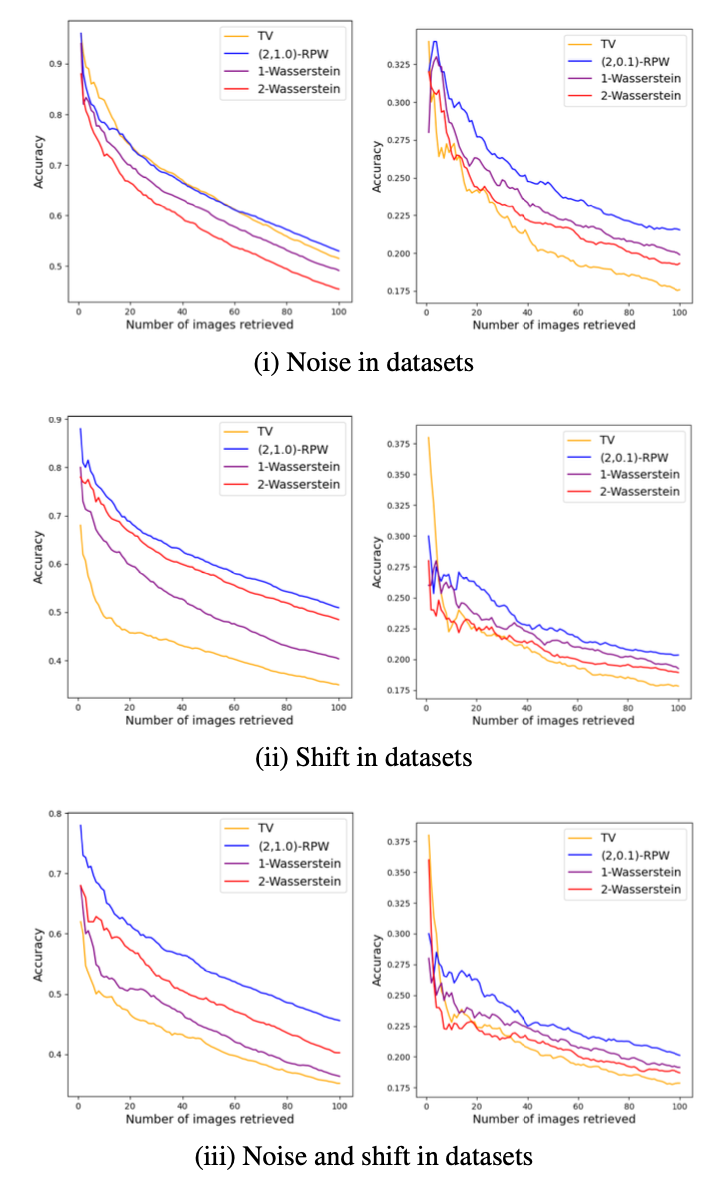
The results of experiments on image retrieval on (left column) MNIST dataset and (right column) CIFAR-10 dataset.
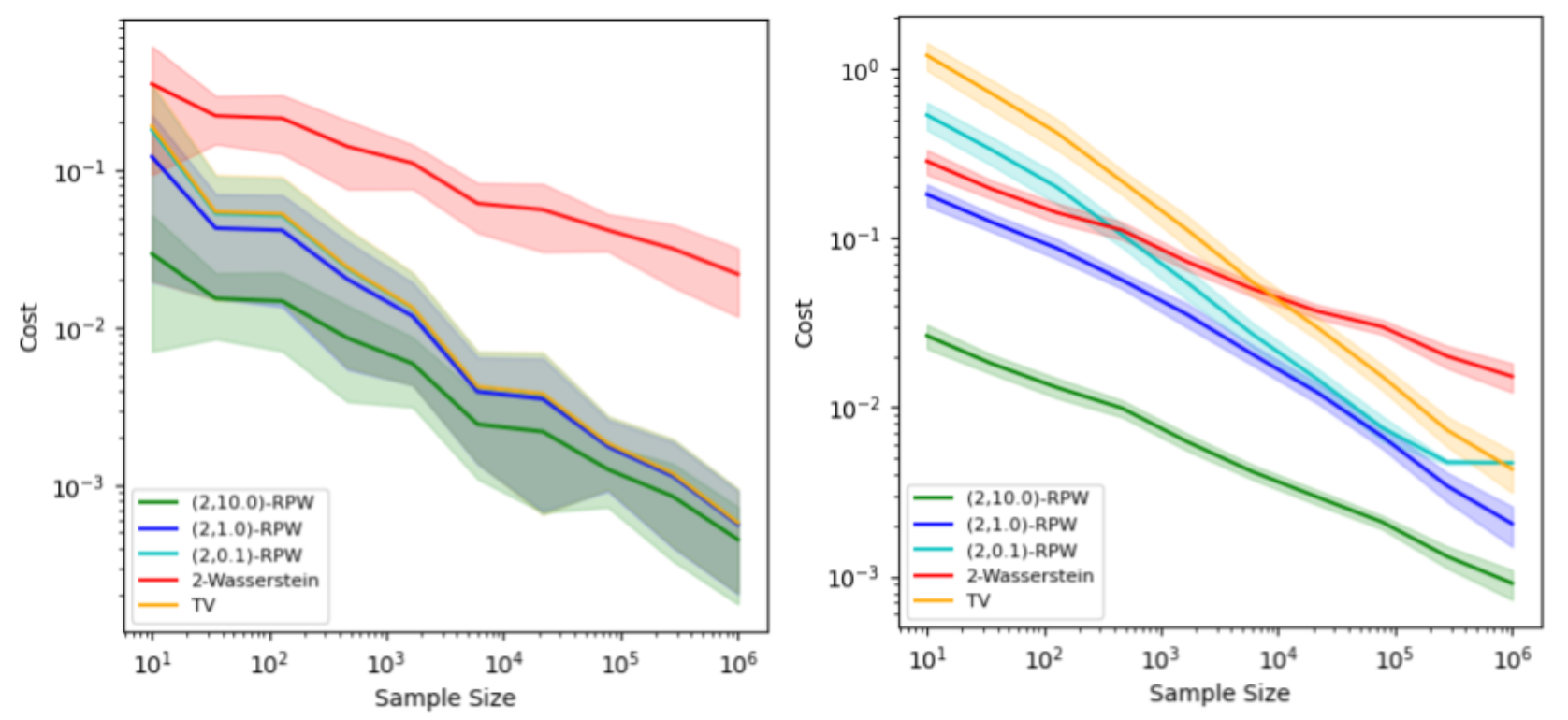
The convergence rate of different metrics on (left) 2-point distribution and (right) grid distribution.
Citation:
@inproceedings{raghvendranew,
title={A New Robust Partial p-Wasserstein-Based Metric for Comparing Distributions},
author={Raghvendra, Sharath and Shirzadian, Pouyan and Zhang, Kaiyi},
booktitle={Forty-first International Conference on Machine Learning}
}